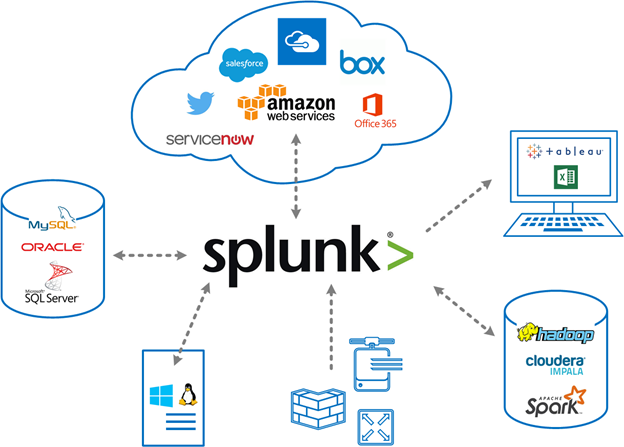
Splunk Data Integration – Getting Data Into Splunk
There are several ways of integrating Splunk within your environment or with your cloud service providers. In this post we will outline some of the many methods you can use to get data into Splunk. In a related post, we will outline some of the many ways to get data out of Splunk.
Discovered Intelligence has implemented all the input methods outlined below for customers. Contact us today to find out more.

Data Input Methods Summary
The following table provides a summary of methods that can be used to get data into Splunk. Each method is then explained further below.
Method |
Description |
| Splunk Universal Forwarder | A light weight forwarding agent for forwarding data to Splunk |
| Splunk Heavy Forwarder | Advanced forwarding agent with parsing and routing capabilities |
| Splunk Modular Inputs | Custom modular inputs for Splunk, including REST API input |
| Splunk DB Connect | Read or write data to or from databases |
| Splunk Hadoop Connect | Import data from Hadoop into Splunk |
| Splunk Stream | Capture and forward real-time network and packet data |
| Splunk HTTP Event Collector | Receive data via HTTP(S) event streams |
Splunk Universal Forwarder
In most cases the use of the Splunk Universal Forwarder (UF) is the simplest method of sending machine data to the Splunk Indexers. The UF is a lightweight agent that can be installed on a server and configured to read and forward any machine-readable data source to Splunk.
The UF can do many things, including reading file contents, receiving syslog, monitoring Windows Events and monitoring registry changes and Active Directory. The UF can also execute scripted inputs, which are particularly useful for preparing data from non-standard sources and is commonly used for polling databases, web services and APIs. You can use shell scripts, python, batch files, PowerShell, etc. UF configurations are typically centrally managed by the Splunk Deployment Server. The UF is great for forwarding Windows Events as it has the ability to blacklist/whitelist certain Windows event codes. One downside of the UF is that it has no real ability to parse or filter data before it is forwarded to Splunk.
More Information on the Splunk UF.
More information on scripted inputs.
Splunk Heavy Forwarder
The Heavy Forwarder (HF) has a larger footprint than the Universal Forwarder, as it is essentially the full blown Splunk software, but configured to only receive and forward data rather than index or search it. The HF differs from the UF in that it can parse and filter the content of the data and take actions on it. The HF can also host Splunk apps, such as DB Connect or Checkpoint to pull data from cloud providers, databases, firewalls and many other sources.
The HF is also sometimes used as a central pass-through for data coming from UFs. For example, HFs are often used to form a ‘forwarding gateway’ before data flows onto Splunk Cloud. This provides a buffer between the many hosts with UFs within an enterprise and the data that flows to Splunk Cloud. The forwarding gateway also allows index time configurations to be applied before data hits the cloud. When using the HF as a pass-through, it is important to properly plan for the capacity to prevent queue build ups and to build in redundancy. For example if you have many UFs flowing through a HF, any downtime of the HF could prevent hundreds or thousands of endpoints from forwarding information to the Splunk Indexers.
Splunk Modular Inputs
Modular inputs can be used to define custom input capabilities and be configured like other Splunk inputs: streaming results from commands (i.e. vmstat), web services and APIs. Many modular inputs have been developed and can be found on Splunk Base, including inputs for SNMP, REST API, JMS, Kafka, AMQP, MQTT, Box, MS Cloud Services and Amazon Kinesis. Modular inputs can also be custom developed using the modular input framework.
More information on Modular Inputs can be found here.
One great app that leverages the modular inputs capability of Splunk is the REST API Modular Input app. This app can be used to pull data from many services that expose data via a REST API, such as Box, Twitter, YouTube, Reddit and Amazon. One of our previous blog posts outlines steps on how to stream data from Twitter into Splunk.
Splunk DB Connect
The DB Connect app allows you to connect to databases and pull data using SQL into Splunk. DB Connect can pull data from an entire table or dataset, poll a database table and maintain database lookups accessible from Splunk. Additionally, it can write data from Splunk to databases. In order to prevent performance impacts on large databases, data pulls can be scheduled during off hours.
Typically DB Connect is installed on a Heavy Forwarder, rather than the main search head or search head cluster, as this approach is often much cleaner and simpler.
More information on Splunk DB Connect.
Splunk Hadoop Connect
The Splunk Hadoop Connect app allows bi-directional integration between Splunk and the Hadoop infrastructure. The app allows you to explore Hadoop directories and files from within Splunk before deciding what data to import. Hadoop can deliver events in their raw or processed form from the Hadoop Distributed File System to Splunk and make it available for searching, reporting, analysis and visualizations.
More information on Splunk Hadoop Connect.
Splunk Stream
Splunk Stream can capture, filter, index and analyze real-time streams of network event data. A stream is a grouping of events defined by a specific network protocol and set of fields. When combined with other data in Splunk, the streams you capture can provide valuable insight into activities and behaviors occurring across the network. Furthermore, users can specify which application-layer protocol to detect, what fields are required to be extracted and aggregate data to reduce data indexing volume. The App comes with pre-built dashboards which visualize network trends and app performance.
While Splunk Stream can be deployed on a Universal Forwarder, there is also a dedicated independent Stream Forwarder. In an independent Stream forwarder deployment, you install the Stream forwarder (streamfwd) binary directly on a Linux machine. Independent Stream forwarder deployment can be useful, for example, if you want to monitor activities on a single Linux host that is part of a network service. No Splunk platform components are required on the Linux host.
More information on Splunk Stream.
Splunk HTTP Event Collector
The Splunk HTTP Event Collector (HEC) enables data to be sent to Splunk from applications via HTTP or HTTPS. Any kind of data can be sent to Splunk through HEC i.e. raw text or formatted within a JSON object. Logging libraries can also be leveraged to package and send data in the correct format. The HEC is token-based and is capable of assigning the incoming data to specific sourcetypes, indexes and indexer groups, to provide more control over the way Splunk consumes the information. The HEC can scale up to very high volumes of incoming data.
More information on the Splunk HTTP Event Collector.
Looking to expedite your success with Splunk? Click here to view our Splunk service offerings.
© Discovered Intelligence Inc., 2017. Unauthorised use and/or duplication of this material without express and written permission from this site’s owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Discovered Intelligence, with appropriate and specific direction (i.e. a linked URL) to this original content.





