
Deploying Cribl Workers in AWS ECS for Data Replay
Cribl Stream provides a flexible way of storing full-fidelity raw data into low-cost storage solutions like AWS S3 while sending a reduced/filtered/summarized version into Analytical Platforms for cost-effectiveness. In this blog post, I’ll walk you through setting up Cribl workers on AWS ECS and implementing dynamic auto scaling for seamless scale-out and scale-in as the demand fluctuates.
When there is a need to re-ingest the data stored in S3, the replay option enables us to selectively replay the data and ingest that into analytical solutions like Splunk. If the volume of data replayed from S3 is high, it will add some additional workload to the workers that’s already handling other data sources and processing. To avoid any performance issues, we can have a separate worker group to handle data replay as given in Cribl’s comprehensive reference architecture.
For cost-effectiveness, the replay worker group can be configured to scale-out on demand and scale in when no longer needed. Using AWS Elastic Container Service with Fargate is a good option for handling the varying workload. With AWS Fargate, we do not need to manage the underlying servers for running the containers.
The Cribl environment I have for the demo purpose has the following components:
- Leader, running on EC2
- NLB to reach leader on port 4200
- A worker group with one worker for handling push sources
I want to send data from a data source to S3 and replay the events when needed and send them to Splunk. For handling this workload, I created a separate worker group where ECS workers will be added and S3 destination and source collector will be configured for writing and reading data from S3. I already have an S3 bucket in AWS for where data will be stored.
The following are the main configuration steps:
IAM policy for ECS service to access S3
The workers created in ECS need to have access to an S3 bucket for storing and reading objects. Create an IAM policy for writing/reading to S3 bucket. Create an AWS Service role in IAM, select ‘Elastic Container Service’ in the services list, and choose ‘Elastic Container Service Task’ from the options.
Here is a sample IAM policy that can be used for this use case:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::<bucketName>",
"arn:aws:s3:::<bucketName>/*"
]
}
]
}Configure Task Definition in ECS
The first step in ECS configuration is Task definition. A task definition is where you define the infrastructure requirements and Docker container configuration details. Go to ‘Amazon Elastic Container Service’ and create a new ‘Task definition’.
Select Launch type as ‘AWS Fargate’, and select the appropriate operating system/Architecture. For this demo, I am using Linux/x86_64.
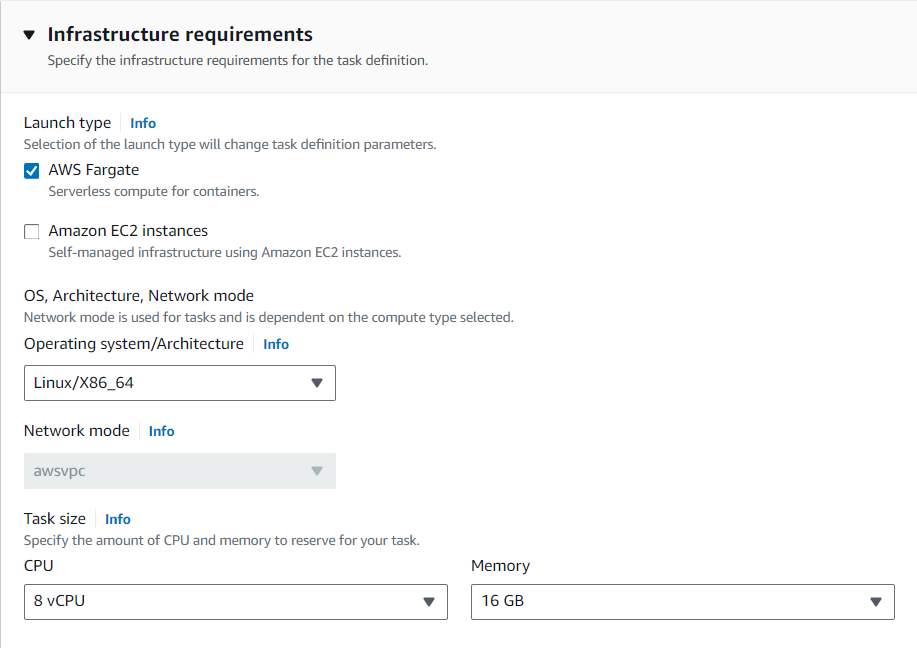
Choose the CPU and memory values to reserve for the task. I am going with 8vCPU and 16GB RAM.
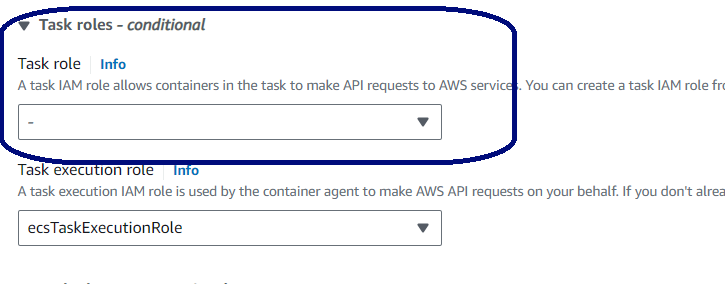
For the Task role, select the IAM role created earlier for accessing the S3 bucket.
In the Container definition, provide the Cribl container details:
- Image URI:- Use cribl/cribl:latest in the image URI. This will pull the latest image of Cribl Stream from the Docker hub. If an older version of Cribl is needed, use the version number instead of the ‘latest’ tag in the image. For example cribl/cribl:4.5.1.
- Port mappings: Add port mappings for the Cribl containers to communicate with the host. In this use case, the containers will be collecting data from S3 and sending it out to Splunk. We do not need any ingestion port to allow inbound traffic.
- Environment variables: This is where we define the Cribl leader configuration. Add the following:
CRIBL_DIST_MASTER_URL - tcp://<token>@<leader_address>:4200?group=<worker_group>
CRIBL_DIST_MODE - worker
Configure ECS Cluster
The second step in ECS configuration is creating an ECS cluster. Select AWS Fargate in the Infrastructure configuration and create the cluster. After a cluster is created, go to Services within the cluster and create a new service.
- Compute Options – I have selected Launch type as the compute option.
- Application Type – Select Service
- Family – Select the task definition created earlier
- Desired tasks – Select 1
- Service Autoscaling – Enable ‘Use service auto-scaling’. Enter the minimum and maximum number of containers allowed for scaling. I am setting it to a minimum of 1 and a maximum of 4 containers.
- Use Target tracking to enable scaling based on a metric like CPU usage.
- Enter a policy Name to use
- Select ‘ECSServiceAverageCPUUtilization’ as the ECS service metric
- Target value – This is where we define the average CPU utilization to maintain in the cluster, based on the target value (70 by default)
- Scale-out cooldown period – enter the amount of time, in seconds, after a scale-out activity (add tasks) that must pass before another scale-out activity can start
- Scale-in cool down period – enter the amount of time, in seconds, after a scale-in activity (remove tasks) that must pass before another scale-in activity can start
- Create the service
Within a few minutes, a container bootstrapped with Cribl will be running in the ECS service. The worker group created for replay is going to show a single worker under it.
Cribl S3 Collector and Destination
Create an S3 destination for writing data to the S3 bucket. In Cribl Docs you will find details on how to setup a destination with partitioning expression. Create a route for sending source data to an S3 destination. For this demo, I am sending the Cribl internal logs to an S3 destination.
Create an S3 collector to read data from the same S3 bucket used in the destination. Run the collector in preview mode to ensure that it is able to see the data in S3. Create a route and pipeline to process the replayed data and send it to the analytical platform (Splunk for example). More details on how setting up Cribl for replay is available here.
To test if the auto-scaling is working, adjust the target value of the CPU in the autoscaling setting to a lower value and run some replay jobs that are expected to bring in a lot of events. If the CPU utilization of the cluster goes above the set value, additional worker instances will be added by ECS to maintain the CPU utilization set for the cluster.
Looking to expedite your success with Splunk and Cribl? Click here to view our Professional Service offerings.
© Discovered Intelligence Inc., 2024. Unauthorized use and/or duplication of this material without express and written permission from this site’s owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Discovered Intelligence, with appropriate and specific direction (i.e. a linked URL) to this original content.








