Splunk Deployment Server: The Manager of Managers
Deploying apps to forwarders using the Deployment Server is a pretty commonplace use case and is well documented in Splunk Docs. However, it is possible to take this a step further and use it for distribution of apps to the staging directories of management components like cluster manager or a search head cluster deployer, from where apps can then be pushed out to clustered indexers or search heads.
The obvious advantage of this approach is that the Splunk admins only have to effectively stage all apps in just one directory – deployment-apps – of one component – the Deployment Server. This centrally consolidates the distribution of apps in one place. The following diagram illustrates this concept.
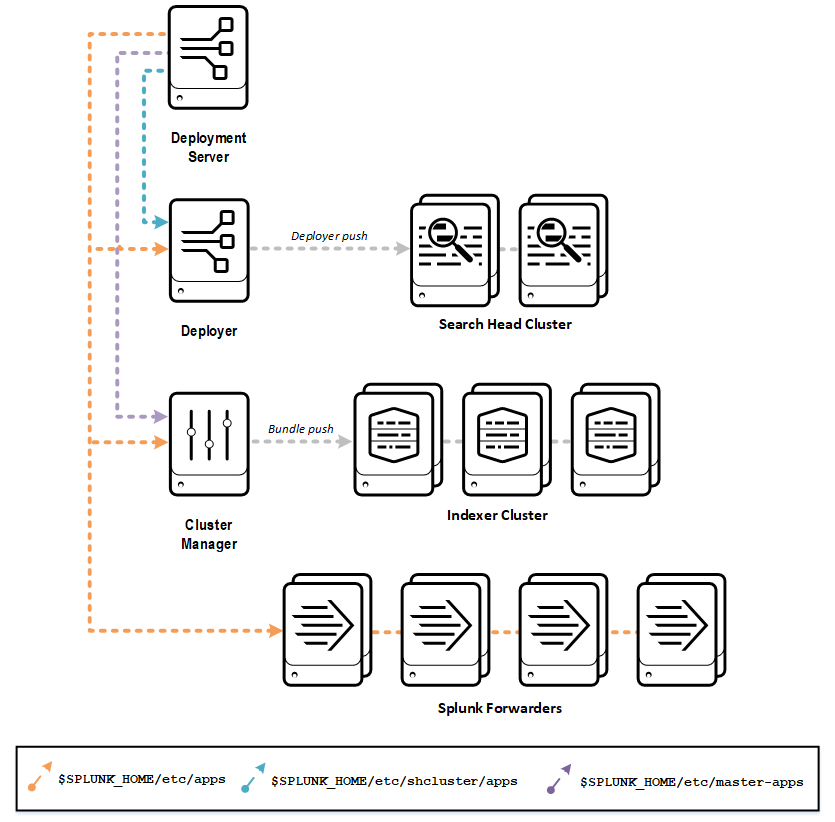
So you’d like to talk to the manager?
Let’s look at how simple this is to implement. All deployment clients polling the deployment server do so using the configuration within the deploymentclient.conf file. Typically this is where we set the deployment server URL and polling interval for that client. There is a configuration attribute repositoryLocation that tells the deployment client where to put the apps it gets from polling the deployment server. The default value for this is $SPLUNK_HOME/etc/apps. However, there is a similar configuration attribute in the serverclass.conf file of the deployment server named targetRepositoryLocation, which tells the deployment server the target location for installation on deployment clients. This setting is also, by default, $SPLUNK_HOME/etc/apps. This gives us two options to achieve our goal of specifying a non-default target location if we want to push apps to a staging location like $SPLUNK_HOME/etc/master-apps on a cluster manager or $SPLUNK_HOME/etc/shcluster/apps on a deployer. Let now look at leveraging these using two different approaches.
Approach#1 – set repositoryLocation on the Deployment Client
For a cluster manager, we can add the snippet below to the deploymentclient.conf:[deployment-client]
serverRepositoryLocationPolicy = rejectAlways
repositoryLocation = $SPLUNK_HOME/etc/apps/master-apps
For a search head cluster deployer, we do the same, like so:[deployment-client]
serverRepositoryLocationPolicy = rejectAlways
repositoryLocation = $SPLUNK_HOME/etc/shcluster/apps
This takes care of configuring the destination location on individual clients. The attribute value pair serverRepositoryLocationPolicy = rejectAlways instructs the client to reject any path provided by the deployment server as the target location and instead use its own repositoryLocation attribute to declare the same.
Ok, so let’s say we have created a serverclass test-cm to manage apps on the cluster manager. Now we want to push an app named org_all_indexes, that contains all indexes to be configured on the indexer tier. See the stanza below for this in the serverclass.conf of the deployment server.[serverClass:test-cm]
whitelist.0 = < cluster manager ip or host name >
[serverClass:test-cm:app:org_all_indexes]
restartSplunkd = false
stateOnClient = noop
Note that the first stanza defines the serverclass test-cm and allow-lists the cluster manager host. The second stanza ties the serverclass with the app. The first attribute of the second stanza restartSplunkd = false tells restart is not required once the app is deployed on the cluster manager and the second attribute stateOnClient is set to noop. This is important because it tells that this app just needs to be staged in the cluster manager and no operations like install or enable is required. That’s it. This way you can attach as many apps as you like to the serverclass and they are all going to land in the cluster manager staging directory and not be installed or enabled.
As you might have noticed, the only difference between how this works for a deployer vs a cluster manager is really the repositoryLocation attribute in the deploymentclient.conf. The rest of the configuration is exactly the same for both components.
The limitation to this approach however is that you give up the ability to manage apps that are ‘installed’ on the cluster manager’s or deployer’s $SPLUNK_HOME/etc/apps folder since you cannot manage more than one repository location in a single deployment client. This is really not of great concern, given the fact that there aren’t as many cluster managers or deployers in a typical Splunk deployment and that the apps required to be installed on these components hardly have configurations that require constant additions or updates.
Approach#2 – set targetRepositoryLocation on the Deployment Server
This is a much simpler and preferred approach as it overcomes the limitation mentioned above as well as only requires update to the serverclass.conf
Again let’s consider the cluster manager, Add the below snippet to the serverclass.conf:
[serverClass:test-cm]
whitelist.0 = < cluster manager ip or host name >targetRepositoryLocation = $SPLUNK_HOME/etc/apps
[serverClass:test-idx]
whitelist.0 = < cluster manager ip or host name >targetRepositoryLocation = $SPLUNK_HOME/etc/master-apps
[serverClass:test-cm:app:org_all_forwarder_outputs]
restartSplunkd = true
stateOnClient = enabled
[serverClass:test-idx:app:org_all_indexes]
restartSplunkd = false
stateOnClient = noop
The above snippet simply defines two serverclasses – test-cm and test-idx – instead of just one in the previous example for the same client, cluster manager in this case, and specifies a non-default target repository location using the attribute targetRepositoryLocation. Any apps that gets attached to test-cm will go to apps directory $SPLUNK_HOME/etc/apps and any apps that gets attached to test-idx will go to the staging directory $SPLUNK_HOME/etc/master-apps, of the cluster manager.
Moreover you also have the flexibility to specify behaviours and states like restartSplunkd and stateOnClient individually for each serverclass. So you can choose to ‘install’ apps and restart splunkd for those apps that go to $SPLUNK_HOME/etc/apps while maintaining a noop state for the ones that go to $SPLUNK_HOME/etc/master-apps for the same deployment client.
Here too, the only difference between how this works for a deployer vs a cluster manager is really the targetRepositoryLocation attribute for each serverclass definition in the serverclass.conf.
There’s always a catch!
There are some things to be aware of when using these approaches including:
- You still have to manually push the apps to the indexers from the cluster manager, or to search heads from the deployer
- Both these approaches should not be used together. i.e. for Approach#2 to work, you need to make sure that the
deploymentclient.confattributes we updated in Approach#1 –serverRepositoryLocationPolicy&repositoryLocation– are set to their default values and not updated on the individual clients – cluster manager or deployer. - These options are not available in the Forwarder Management UI. So as the
serverclass.conffile grows in size with more configurations, manually editing the file could potentially lead to incompatibilities which, when you return to the Forwarder Management UI, will generate error messages in appropriate locations in the interface. As long as the incompatibilities persist, you will not be able to configure via the forwarder management interface.
Conclusion
What we covered here is a native option in Splunk to augment the usability of the deployment server component in managing apps across a clustered Splunk deployment. I highly recommend reading this in conjunction with an earlier blog I wrote about automating the staging of deployment apps in the deployment server using GitHub Actions linked here. This blog serves as a technical addendum to the linked article. I will soon be publishing a sequel to the linked blog that will let you administer the deployment server fully out of a GitHub repository so the entire deployment configuration and apps are version-controlled and can easily be rolled back to a previous version if so required. Stay tuned.
Useful Links
- Use deploymentclient.conf to declare target location
- Use serverclass.conf to define server classes
- Moving bits around: Deploying Splunk Apps with Github Actions
© Discovered Intelligence Inc., 2022. Unauthorized use and/or duplication of this material without express and written permission from this site’s owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Discovered Intelligence, with appropriate and specific direction (i.e. a linked URL) to this original content.







{kind=link}